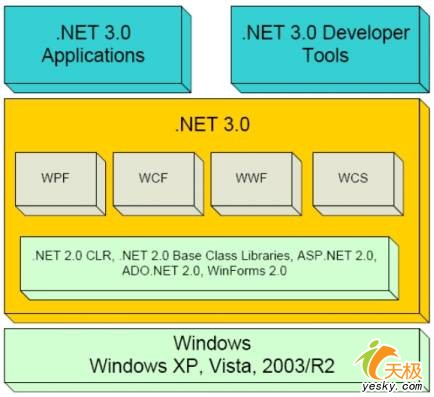
文章目录
- 前言
- 数据展示
- 评星比例图
- 地理位置分布图
- 词云图
- 完整代码
- 总结
前言
今天我将用数据告诉你电影《少年的你》到底值不值得看,废话不多说,直接进入今天的正题吧!

数据展示

数据是我用爬虫从猫眼上爬下来的,具体操作见博文猫眼电影影评爬取
评星比例图
首先,给大家展示一下这部电影的评分比例。
def pie_show() -> Pie:
c = (
Pie()
.add("", [list(z) for z in zip(star, values)])
.set_global_opts(title_opts=opts.TitleOpts(title="《少年的你》评星"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%"))
.render('result/评星.html')
)
return c

地理位置分布图
接着我们再来看一下,评分人的地理位置分布。
def geo_show() -> Geo:
c = (
Geo()
.add_schema(maptype='china')
.add("", [list(z) for z in zip(city_name, city_position)])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(visualmap_opts=opts.VisualMapOpts(), title_opts=opts.TitleOpts(title="《少年的你》评星人位置分布图 by CSDN-虐猫人薛定谔i"))
.render('result/位置分布图.html')
)
return c

词云图
最后,看一下电影评论的词云图,通过词云图你也就大概知道电影的主题了。
def wordcloud_show():
comment_split = jieba.cut(str(comments), cut_all=False)
words = " ".join(comment_split)
# 过滤掉无用的词
stopwords = STOPWORDS.copy()
stopwords.update({"虽然", "但是", "这部", "还是", "一个", "电影", "最后", "而且", "感觉"})
background_img = plt.imread('res/bg.jpg')
# 产生词云
wc = WordCloud(
width=454,
height=442,
background_color="white",
max_words=200,
mask=background_img,
stopwords=stopwords,
max_font_size=200,
random_state=50,
font_path='C:/Windows/Fonts/simkai.ttf'
).generate(words)
image_colors=ImageColorGenerator(background_img)
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.show()
wc.to_file('result/词云图.png')

完整代码
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/1/22 19:49
# @Author: Martin
# @File: 少年的你.py
# @Software:PyCharm
import jieba
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from pyecharts.charts import Geo
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ChartType, SymbolType
from pyecharts.datasets import COORDINATES
# 读取数据
data = pd.read_csv('./result/maoyan.csv', encoding='utf-8_sig')
star = ['一星', '两星', '三星', '四星', '五星']
score = data.groupby('score').size()
cities = data.groupby('cityName').size()
cities = cities.to_dict()
comments = data['content'].tolist()
values = [
score.iloc[0] + score.iloc[1],
score.iloc[2] + score.iloc[3],
score.iloc[4] + score.iloc[5],
score.iloc[6] + score.iloc[7],
score.iloc[8] + score.iloc[9]
]
total = 0
for i in values:
total += i
for i in range(0, len(values)):
values[i] = values[i] / total * 100
# 设置匹配阈值
COORDINATES.cutoff = 0.7
# 城市坐标处理
city_name = []
city_position = []
for key in cities:
result = Geo().get_coordinate(key)
if result is None:
continue
else:
city_name.append(key)
city_position.append(result)
def pie_show() -> Pie:
c = (
Pie()
.add("", [list(z) for z in zip(star, values)])
.set_global_opts(title_opts=opts.TitleOpts(title="《少年的你》评星"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%"))
.render('result/评星.html')
)
return c
def geo_show() -> Geo:
c = (
Geo()
.add_schema(maptype='china')
.add("", [list(z) for z in zip(city_name, city_position)])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(visualmap_opts=opts.VisualMapOpts(), title_opts=opts.TitleOpts(title="《少年的你》评星人位置分布图 by CSDN-虐猫人薛定谔i"))
.render('result/位置分布图.html')
)
return c
def wordcloud_show():
comment_split = jieba.cut(str(comments), cut_all=False)
words = " ".join(comment_split)
# 过滤掉无用的词
stopwords = STOPWORDS.copy()
stopwords.update({"虽然", "但是", "这部", "还是", "一个", "电影", "最后", "而且", "感觉"})
background_img = plt.imread('res/bg.jpg')
# 产生词云
wc = WordCloud(
width=454,
height=442,
background_color="white",
max_words=200,
mask=background_img,
stopwords=stopwords,
max_font_size=200,
random_state=50,
font_path='C:/Windows/Fonts/simkai.ttf'
).generate(words)
image_colors=ImageColorGenerator(background_img)
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.show()
wc.to_file('result/词云图.png')
if __name__ == '__main__':
pie_show()
geo_show()
wordcloud_show()
总结
通过这次数据分析实战,我学到了一些常用的数据可视化的方法,进一步了解了词云图以及pyecharts。

对数据可视化感兴趣的小伙伴可以相互关注,一起交流,一起学习,共同进步。

By 虐猫人薛定谔i 2020年1月24日写于家中