今天写了一个简单增量插入三元组的程序
1、查找实体类型对应的实例,放入list中,用于实例查重:
# 查找实体类型对应实例,返回list
def get_all_entities_of_ent_typ(graph, ent_typ):
matcher = NodeMatcher(graph)
ent_list = list(matcher.match(ent_typ))
ent_list = [ent['name'] for ent in ent_list]
return ent_list2、对三元组中头实体已存在、尾实体已存在、三元组存在、三元组不存在来对实体进行处理,如果存在当前实体类型对应的实例则合并,不存在则插入。
3、关系通过简单的设定是否允许存在1对多和多对1的关系来提前设定。
# 三元组插入neo4j
def triples2neo4j(graph, triples, one2many=False, many2one=False): # 允许一对多关系,允许多对一关系
for triple in triples:
# 取出头实体、尾实体、关系
ent_1, ent_2, rel = triple
head, head_typ = ent_1
head_node = Node(head_typ, name=head)
tail, tail_typ = ent_2
tail_node = Node(tail_typ, name=tail)
# head类型list
head_list = get_all_entities_of_ent_typ(graph, head_typ)
# tail类型list
tail_list = get_all_entities_of_ent_typ(graph, tail_typ)
# 头实体和尾实体都存在
if head in head_list and tail in tail_list:
graph.merge(head_node, head_typ, "name")
graph.merge(tail_node, tail_typ, "name")
if list(RelationshipMatcher(graph).match((head_node, tail_node), r_type = rel)):
print(f'三元组 ({head} ,{tail} ,{rel}) 已存在于图谱中,插入失败!')
else:
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 头实体已存在
elif head in head_list and tail not in tail_list:
graph.merge(head_node, head_typ, "name")
if list(RelationshipMatcher(graph).match((head_node, None), r_type = rel)):
if one2many == False:
print(f'头实体 {head} 已存在关系 {rel} 对应的三元组 ({head} ,{tail} ,{rel}),插入失败!')
continue
graph.create(tail_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 尾实体已存在
elif head not in head_list and tail in tail_list:
graph.merge(tail_node, tail_typ, "name")
if list(RelationshipMatcher(graph).match((None, tail_node), r_type = rel)):
if many2one == False:
print(f'尾实体 {tail} 已存在关系 {rel} 对应的三元组 ({head} ,{tail} ,{rel}),插入失败!')
continue
graph.create(head_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 头实体、尾实体均不存在
else:
graph.create(head_node)
graph.create(tail_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')所有代码如下:
# 查找实体类型对应实例,返回list
def get_all_entities_of_ent_typ(graph, ent_typ):
matcher = NodeMatcher(graph)
ent_list = list(matcher.match(ent_typ))
ent_list = [ent['name'] for ent in ent_list]
return ent_list
# 三元组插入neo4j
def triples2neo4j(graph, triples, one2many=False, many2one=False): # 允许一对多关系,允许多对一关系
for triple in triples:
# 取出头实体、尾实体、关系
ent_1, ent_2, rel = triple
head, head_typ = ent_1
head_node = Node(head_typ, name=head)
tail, tail_typ = ent_2
tail_node = Node(tail_typ, name=tail)
# head类型list
head_list = get_all_entities_of_ent_typ(graph, head_typ)
# tail类型list
tail_list = get_all_entities_of_ent_typ(graph, tail_typ)
# 头实体和尾实体都存在
if head in head_list and tail in tail_list:
graph.merge(head_node, head_typ, "name")
graph.merge(tail_node, tail_typ, "name")
if list(RelationshipMatcher(graph).match((head_node, tail_node), r_type = rel)):
print(f'三元组 ({head} ,{tail} ,{rel}) 已存在于图谱中,插入失败!')
else:
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 头实体已存在
elif head in head_list and tail not in tail_list:
graph.merge(head_node, head_typ, "name")
if list(RelationshipMatcher(graph).match((head_node, None), r_type = rel)):
if one2many == False:
print(f'头实体 {head} 已存在关系 {rel} 对应的三元组 ({head} ,{tail} ,{rel}),插入失败!')
continue
graph.create(tail_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 尾实体已存在
elif head not in head_list and tail in tail_list:
graph.merge(tail_node, tail_typ, "name")
if list(RelationshipMatcher(graph).match((None, tail_node), r_type = rel)):
if many2one == False:
print(f'尾实体 {tail} 已存在关系 {rel} 对应的三元组 ({head} ,{tail} ,{rel}),插入失败!')
continue
graph.create(head_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
# 头实体、尾实体均不存在
else:
graph.create(head_node)
graph.create(tail_node)
graph.create(Relationship(head_node, rel, tail_node))
print(f'三元组 ({head} ,{tail} ,{rel}) 插入成功!')
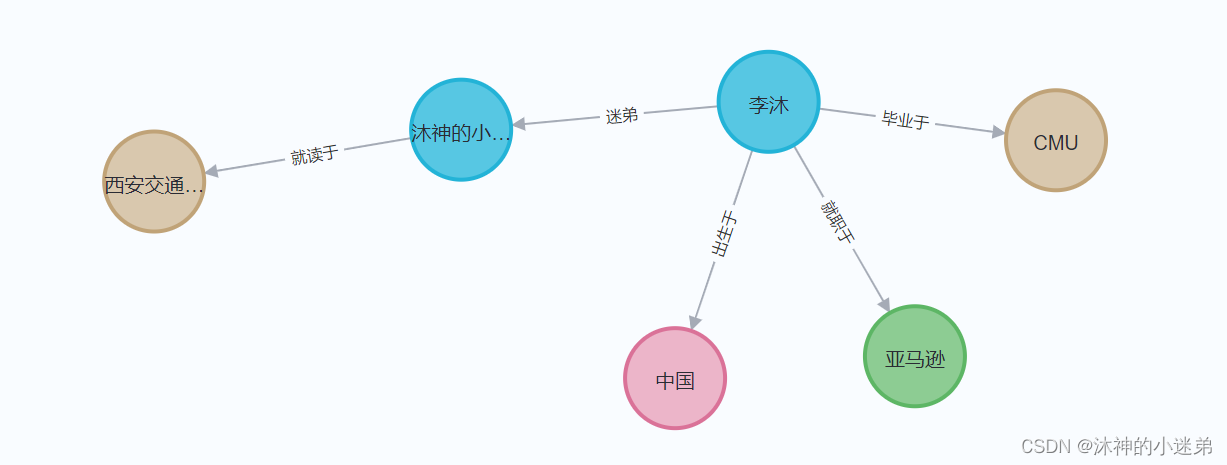
triples = [
(['李沐','Per'], ['CMU', 'Sch'], '毕业于'),
(['李沐', 'Per'], ['沐神的小迷弟', 'Per'], '迷弟'),
(['李沐','Per'], ['中国', 'Cou'], '出生于'),
(['李沐','Per'], ['亚马逊', 'Com'], '就职于'),
(['沐神的小迷弟', 'Per'], ['西安交通大学', 'Sch'], '就读于'),
(['李沐','Per'], ['上海交通大学', 'Sch'], '毕业于'),
(['李沐','Per'], ['百度', 'Com'], '就职于'),
]
triples2neo4j(graph, triples, one2many=False, many2one=False)运行结果: